
R. Grossman, X. Qin, and W. Xu
Oak Park Research, Inc.
Oak Park, Illinois
H. Hulen and T. Tyler
IBM Government Systems
Houston, Texas
This is a draft of the paper: R. Grossman, X. Qin, W. Xu, H. Hulen, and T. Tyler, An Architecture for a Scalable, High-Performance Digital Library, 14th IEEE Symposium on Mass Storage Systems, IEEE Press, pages 89-98, 1995.
This paper describes the architecture of a prototype system that allows users to retrieve and browse information related to a topic of interest from a terabyte of multimedia data. We focused on six key requirements. The requirements are referenced later in the paper by the short titles, shown in italics:
The quick access, large stores, and fast transfers requirements suggest a high-performance storage system. Requirements for quick access, complex types, and transparent services suggest a high-performance persistent object manager, as we will discuss in detail below. This grouping of the requirements suggests the importance of interfacing storage management and data management, which is one of the areas of interest in this conference. The requirement for friendly access relates to the interface between the object management layer and external applications.
Although as a community our primary interests may lie in the design and development of storage management systems, our users are increasingly concerned with the design and development of data management systems. During the next several years, one expects that users' interests will migrate to focus on interfaces to data management systems, rather than the data management systems themselves. Developing a layered architecture with appropriate interfaces between the layers is therefore of increasing importance.
We begin by providing some background material about digital libraries and data mining. Next, we propose an architecture to satisfy the requirements introduced. We then discuss some of the key components of the object management layer of the architecture. Following this, we discuss some of the key components of the storage management layer of the architecture. Next we discuss the interface between the storage management and the object management layers. We then include discussion about services and agents. And finally we describe our initial testbed, some early experiments, and our conclusion.
A digital library centers on the discovery and delivery of information. A database, in contrast, has historically been concerned with transactions, backup, recovery, and integrity. The transactional nature of the database comes from the requirement that many users are empowered to change data. Both the database and the users must be protected from errors that can arise when two or more users try to concurrently access and change the same data, or when failures occur in the middle of a sequence of accessing and changing data. Consider the example of a database, either object or relational, used in the development of a reservations system. In this classic application, a paramount concern is the integrity of transaction updates. It would be unacceptable, for example, to assign the same seat to two individuals. Therefore, the database manager must be concerned with the completion of one transaction (the assignment of a seat) before any other transaction is allowed to attempt to reference or change the same data (the assignment of the same seat again).
A digital library is built on the model of data mining. By digital library we mean a system that is primarily designed for selecting, retrieving, and computing with complex data. The premise is that most users will only read the data, and that only selected users will add to or change the data. The digital library therefore has a more relaxed requirement for transactional integrity than the database has. Therefore the digital library is a candidate for a simpler or more lightweight solution. Consider the example of a digital library of journal articles, maps, photos, and TV news clips. The goal of such a library might be to allow many users to search through all types of data and retrieve relevant entries. The process of putting the data in the library, called ingestion, is done at a few key points in the system, and transaction processing (atomicity) is required only to the extent of protecting the name space and other metadata. Because the data-mining model is simpler than the database model, there is incentive to use a simpler capability, such as an object store with a persistent object manager, rather than a full-function object-oriented or relational database.
We begin our discussion of the data model with a general discussion of object stores in order to fix definitions. An object is an abstract data type together with some functions, or methods, for creating, accessing, and modifying it. An object is called persistent if it continues to exist once the process that creates it terminates; otherwise, the object is called transient. An object manager is a process that can create and manage persistent collections of objects, called stores. An object-oriented database is an object manager with additional functions such as transactions, concurrency, backup, and recovery. In the context of object stores, an element of the abstract data type is called an attribute of the object.
The decision to use an object data model instead of a relational data model for digital library applications is based on the complexity of the data. The object data model carries with it no assumptions about the structure of the data. A relational model, in contrast, is burdened by the assumption that data must be organized into rows and columns. A complex piece of data such as a TV news clip or hypertext fits much more easily into the object model. Proponents of the relational model address this difficulty by creating the abstraction of a Binary Large Object or blob. A blob may be stored either in the database or in a separate file, but the key to its accessibility is putting metadata about the blob in traditional relational form. The Binary Large Object extension to the relational model is of interest when an existing relational database is being extended to new complex data types or when other aspects of the database program are important.
Another alternative is to use a relational object model or a relational model with pointers to objects. These models integrate well with legacy data stored in relational databases or with legacy systems built upon relational databases. On the other hand, they do not present any direct advantages for new systems. For this reason, we have not used these types of hybrid models.
For the current project we are using the object model. Our application fits the above rationale for the object model: there are large, complex data types and there is no requirement for a relational or other predetermined paradigm. In such situations, the advantages of using an object data model instead of a relational data model for complex data are well established. In addition, we have found that mining large amounts of complex data is more efficient using an object model, since in practice this allows expensive multiple joins to be replaced with inexpensive projections [1].
Under the object model, customized access routines are created for each data type. The access routines, called methods, hide the complexity of the data type from the user. As in the example above, different viewers are appropriate for different data types and for different hardware and networking environments.
In this section, we consider the relationship between data management and storage management. Data management, as we define it, provides storage and retrieval based on the content of the data. Storage management deals with the containers, such as bitfiles and logical and physical volumes, into which data is organized. Clearly, both are needed; one must know both the content of a bitfile and something about what contains it in order to make use of it. Database management systems have traditionally provided high function in dealing with data content but tend to treat the containment side in a simplistic way when compared to storage systems. Storage systems offer greater capabilities than database systems for distributing data on a network, moving data up and down a hierarchy of device types, and accessing large amounts of it rapidly, but storage systems have no knowledge of the information content of any container.
It has long been a goal of the IEEE Mass Storage Systems and Technology Technical Committee to find a way to bring data management and storage management together in a synergistic way. The IEEE Mass Storage System Reference Model, Version 5, contemplates the use of storage systems in a layered architecture in which a data management system would obtain access to storage through a storage system. This project makes use of such a layered model. Recently, a need for a standard model for lightweight, high-performance data management has arisen, and a strawman proposal has been put forth [2]. The data management layer is a lightweight, high-performance, persistent object manager that is compatible with this proposal. The storage layer is a scalable storage system with parallel and distributed capability that is compatible with the IEEE Mass Storage System Reference Model.
Our architecture is designed to support numerically intensive queries and to balance input-output and processing requirements of applications. This allows us to support a broad range of digital library applications, including scientific digital libraries and data-mining queries on data warehouses, in addition to the more common collections of hypertext or multimedia documents.
The fast transfers requirement from the introduction suggests parallel access to the storage system. Parallel input-output improves the performance of our digital library in several ways. First, with terabyte-sized digital libraries, it is inevitable that some queries will require access to data that has either been staged to tertiary media or requires gathering data that has been scattered to different nodes. Parallel input-output improves the delivery of staged data and data that has been scattered over several nodes. Second, multimedia objects can be very large. Parallel input-output is a practical way to improve the delivery speeds of multimedia data.
For concreteness, consider a digital library containing a collection of multimedia documents, each of which is an object of the following form:
Title, Author, Date, Content, and so on, are themselves objects whose particular structure need not concern us here. The Content object may itself contain other document objects. In the terminology of databases, documents are complex objects [3]. Complex objects are supported by object data models, but not by relational data models. This relates to the complex types requirement.
Each document has a Format attribute. This attribute can be used so that different documents can use different input-output paths. Just as the IEEE Mass Storage System Reference Model separates control and data paths, attributes in objects can be used so that the object manager can exploit different data paths and protocols for text, images, and video. In other words, object-specific transport and visualization methods can be used. This relates to the transparent services requirement.
Different types of multimedia documents have different input-output requirements. Consider a top-level complex textual document, containing embedded images and video. Different components of this complex document require different types of input-output protocols and delivery mechanisms. For example, the embedded video document may be striped across disks to improve performance. This relates to the fast transfers requirement.
To continue with this example, consider a collection of documents called US_Mediaand the following query:
The intent of the query is to return the title and summary of all stories containing the keywords ``Information'' and ``Superhighway'' written after 1994, such that the summary contains the phrase ``economic impact.'' The summary of the article is itself a complex object with subobjects. This also relates to the complex types requirement.
Collections, such as US_Mediain the example above, may be very large. This is especially true if the collections contain images and video. For this reason, some type of hierarchical storage system is required. This relates to the large stores requirement.
Finally, note that a user's goal is to retrieve and browse documents related to his or her interest. The user is not interested in knowing the name of the document nor in being forced to find the document by navigating from some known reference point. This relates to the friendly access requirement. In this paper we use Object Query Language (OQL), an emerging standard for retrieving objects by attributes, as an interface to a persistent object store of documents. What is important here is not the particular interface, but rather any interface that provides a means to access a collection of documents by attribute.
We begin with an overview of the architectural model. Our model is layered and illustrated in Figure 1. Here we briefly describe the key features:
At the bottom layer is a hierarchical storage system. The hierarchical storage provides the basic mechanisms for managing the terabyte-sized digital libraries. In addition, the storage system supports parallel input-output, which increases performance. This increased performance is especially important for specialized services, such as video services. The storage system interfaces to other layers through application program interfaces (APIs) supported by the IEEE Mass Storage System Reference Model [4].
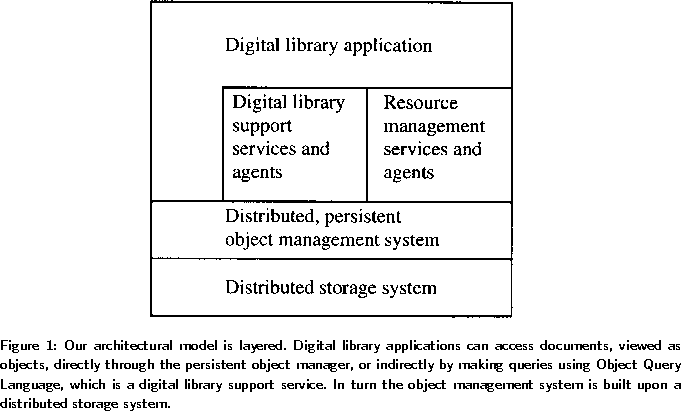
The next layer is the persistent object management system. As mentioned above, the digital library consists of complex objects that contain or point to other objects. In addition the objects have attributes, which are the basis of queries. The object management system creates, accesses, and updates these objects. The persistent object management system also supports parallel input-output in a manner compatible with the parallel input-output supported by the storage system. The object management system interfaces to other layers through the lightweight object management APIs proposed in [2].
A digital library application can access documents directly through the persistent object manager or indirectly through digital library support services. A basic example of such a support service is an Object Query Language (OQL) tool, supporting Select, From, and Where queries, as in the example from the last section.
The final component in the model consists of resource management services and agents. Given a large amount of distributed data, it is a challenging problem to locate the relevant resources. Moreover, the management of the underlying physical resources comprising the object management and storage management systems is also a problem. A resource management agent can be used, for example, to locate a collection so that an appropriate query can be applied to it.
Underlying our approach is the view that access to data for digital libraries should be through object managers, as illustrated in Figure 1. Object managers provide advantages over both file-based access and database access to data:
The layer above the persistent object management system consists of digital library support services. For terabyte-sized object stores, the management of the physical and logical resources becomes critical. The physical location of auxiliary indexing information must, for efficiency, be managed by the persistent object management system itself, and not by the underlying storage system. Resource management tools can be used to keep track of these changes. At the top layer are the digital library applicationsthemselves.
Our prototype uses AIM Net for the object management layer which is a product of Oak Park Research, Inc. AIM Net is a system for archiving, integrating and mining large amounts of data that is based upon a lightweight object management system compliant with the API proposed in [2]. In this section, we describe architectural features and components of AIM Net that relate to this project.
Recent advances in programming languages, operating systems and compilers make the development of a lightweight, high-performance persistent object management system relatively straightforward ([5],[6]). Rather than go into detail here, we will simply discuss two of the key ideas.
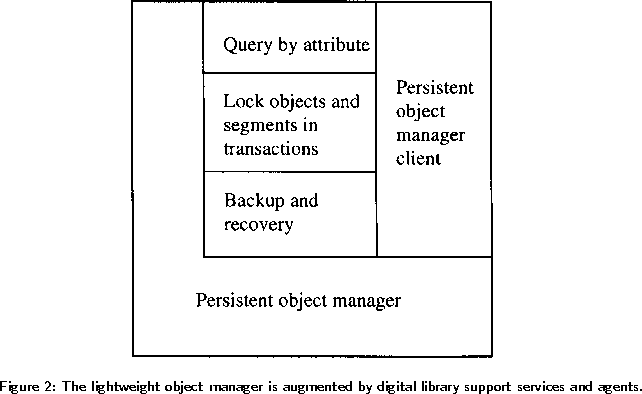
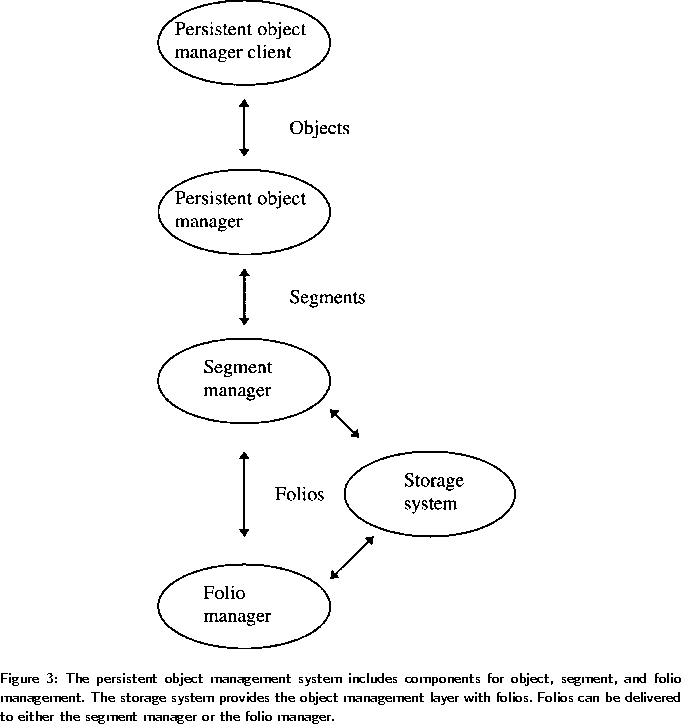
Figure 3 also illustrates the managers associated with objects, segments, and folios. The Persistent Object Manager itself creates and accesses persistent objects. It also creates, opens, and closes stores. If the segment containing a referenced persistent object is not currently available in virtual memory, the Persistent Object Manager generates a fault to the Segment Manager. If the segment is available in the local disk cache, it is returned to the Persistent Object Manager to be mapped into virtual memory. If the segment required by the Segment Manager is not available in the local disk cache, then the Segment Manager generates a fault to the Folio Manager. The Folio Manager then determines the location of the folio containing the required segment, retrieves the folio, extracts the segment, and returns the segment to the Segment Manager.
The hierarchy of physical collections offers flexibility. Segments and folios may be implemented differently. For example, both segments and folios may be implemented as files. As an alternative, segments may be managed directly by the persistent object management level, while folios may be managed by a storage system layer. This is an issue discussed in more detail in the next section, which deals with the interface between the data management and storage management layers.
The client API for the persistent object manager is based upon a strawman proposal for lightweight object management [2]. To create persistent instances of the Document class and add them to the persistent object store called DocumentStore, consider the following C++ code fragment that creates a transient instance of the class Document and assigns Lewis as the author:
Item *transient\_document\_pointer;
transient\_document\_pointer =
new Document;
strcpy(transient\_document\_pointer
->author, "Lewis");
The above code can be replaced by the code fragment which creates persistent instances:
Store d\_store( "DocumentStore" );
PPointer<Document>
persistent\_document\_pointer;
new( d\_store,
persistent\_document\_pointer )
Document;
strcpy(persistent\_document\_pointer
->author, "Lewis");
In other words, by adding one line naming the persistent object store and by changing the declaration of the pointer, one can work with persistent instances of the class. To access persistent Documents is equally simple.
Our prototype uses the High Performance Storage System (HPSS) for the storage management layer [7]. HPSS is the result of a collaboration between IBM and four Department of Energy labs: LLNL, LANL, ORNL, and SNL. The HPSS Project is committed to open, public-domain interfaces and invites the development of pluggable components. HPSS is an evolving system designed to take advantage of current and future hardware and software technology.
In this section, we give brief descriptions of four key ideas from the storage system layer of our system relevant to our architecture and describe how these ideas are used in our digital library.
In this section, we give very brief descriptions of the two components of the storage system layer which interface to the object management layer as background for the discussion in the next section. As we will discuss in more detail below, we focus on these two components of the storage system since they provide alternate interfaces for storage system clients, such as the persistent object management layer. Initially we are using the Bitfile Server interface. We expect that, at least in certain cases, we will need to interface to the Storage Server to gain better performance and more refined control of the physical placement of data, despite the greater complexity this involves.
The Bitfile Server is the storage system component that provides the abstraction of logical bitfiles to its clients. A logical bitfile is simply an uninterpreted string of bits. The Bitfile Server exports interfaces for creating, unlinking, opening, closing, reading, and writing bitfiles, in addition to other operations like lseek. It supports file sizes up to 2**64 bytes, file gaps (that is, places in the file where data has not been written), parallel data movement, migration, and purging. It maps bitfiles and portions of bitfiles onto lower-level storage abstractions provided by the Storage Server.
The Storage Server provides a hierarchy of storage objects called storage segments, virtual volumes, and physical volumes. Physical volumes map to physical media such as disk and tape volumes while virtual volumes logically group one or more physical volumes. For example, a four-way striped-disk virtual volume would group four different disk physical volumes into one virtual volume. Finally, storage segments represent space allocated on virtual volumes and are made available to the Bitfile Server for storing bitfile segments. The Storage Server provides APIs for manipulating physical volumes (create, delete, mount, unmount, read, and write), manipulating virtual volumes (create, delete, mount, unmount, read, and write) and manipulating storage segments (create, unlink, read, write, mount, unmount, copy, and move).
As a legacy of the AIM Net design, it is the responsibility of the data management layer to place and cluster data appropriately for optimal access by the applications. The data management and storage management interfaces are made more complex by the desire for parallel input and output. Parallel input-output implies that physical collections of objects must be placed in certain relative locations that must be carefully coordinated with the storage system's interest in caching and migrating physical storage.
Segments of objects are slotted into virtual memory and may be striped over several disks to improve performance. Segments are managed by the Segment Manager, and hence striping may be managed by the persistent object (data) management layer.
Because the design of HPSS was based on the IEEE Mass Storage System Reference Model, its modular and layered architecture allows client applications to communicate with lower-level services. For example, we are currently investigating having the Segment and Folio Managers communicate directly with the Storage Server as a possible way to optimize access to storage segments. This interface might also be used in strategically managing the location of collections of related object data throughout the available storage media hierarchies. Optimizing this interface is an area of current interest.
Options for the interface between AIM Net and HPSS are shown in Figure 4. There are potentially four interfaces between segment server and folio server of the data management layer (AIM Net) and the Bitfile Server and Storage Server of the Storage System layer (HPSS). The four interfaces are numbered in Figure 4 in the shaded area between the two layers. There are, of course, many ways to construct each interface.
In the initial design, the Folio Manager will be adapted to access tape managed by the storage system. Tape access may be serial, using a single tape, or the parallel-tape capabilities of HPSS can be used. This is represented by interface 1 in Figure 4.
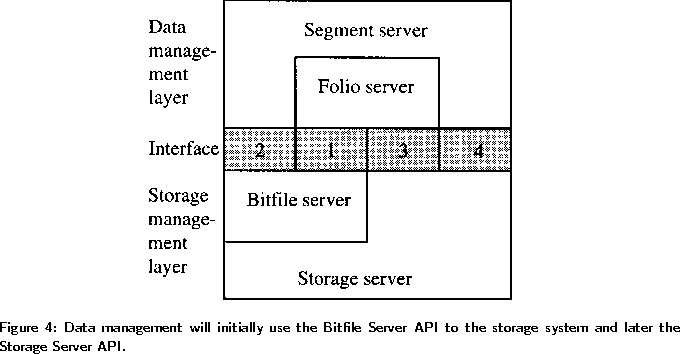
One approach is for the storage system to retrieve a requested folio, extract the segments, and stripe them across the appropriate disks using the Parallel Transport Protocol (PTP). This corresponds to interfaces 2 and 4 in Figure 4. Another approach is for the storage system to return the folio to the Folio Manager and for the Folio Manager to stripe the segments across the appropriate disks. This corresponds to interface 1 or 3. A third option is to use a mixture of the two approaches, depending upon the application. We are currently investigating each of the three approaches.
In this section, we discuss briefly several issues involving services and agents. These are part of the digital library support service layer, which is above the object management system layer.
Supporting complex objects provides only limited benefit without the ability to query them by attribute. Object Query Language (OQL) is an emerging standard for querying objects, broadly analogous to SQL. OQL allows one to select objects and specified attributes from a named collection of objects where a given predicate holds. The where clause may be a simple Boolean expression or may contain functions from an embedded programming language. See the example from the second section. With a suitable, application-specific front end, we have found OQL more than adequate for a variety of applications. In our architecture, an OQL service is provided as one of the digital library support services, as illustrated in Figures 1 and 2. Notice that we do not make it part of the object management layer, which is consistent with our philosophy of providing lightweight object management as the basis for digital libraries.
With a terabyte-sized digital library, it is just as important to be able to locate a desired collection of documents as it is to query a collection, once the desired collection has been located. In our architecture, it is the role of agents called Query Request Agents to locate desired collections on the basis of their attributes. Query Request Agents are another example of a digital library support service that is layered over the object management system. We do not go into detail in this paper, but simply give the general idea.
Our approach is to view collections of objects as objects themselves. Metadata about collections can then be viewed as attributes, and OQL type queries can then be used to locate desired collections. This approach allows us to use the object management system itself to manage collections. Another benefit of this approach is that very large collections can be located and worked with in this fashion. For example, the attributes comprising the metadata may be quite large and might not fit onto a single disk. This does not present a problem when they are handled by the object management system but conceivably could present a problem if handled in another way.
Although not of direct concern in this paper, we mention briefly how our architecture exploits highly parallel architectures. Consider a node in a cluster that requires a physical collection of objects to satisfy a query. The requesting node uses the Query Request Agent to locate the node in the cluster containing the required data. The query can then either be moved to the data or the data to the query. This is done by using a peer-to-peer architecture for processes requesting and returning the physical collection. In this way, we can exploit data-centered parallelism in clusters and parallel supercomputers.
We can also exploit parallel processing environments by distributing Query Request Agents across nodes. Multiple processors can share high-performance secondary and tertiary storage devices and still provide high-performance to large numbers of incoming queries. To support this approach, we simply need to route an incoming query to any node with a Query Request Agent that has a short queue of queries.
Finally, we exploit parallel-processing environments by breaking queries into subqueries and distributing the subqueries across the nodes. Currently this must be done in an application-specific fashion.
To test this architecture for a scalable, high-performance digital library, Oak Park Research, Inc. and IBM Government Systems have put together an initial testbed and plan to scale up this testbed to create a terabyte-sized digital library of multimedia data called the AIM Net High Performance Digital Library (HPDL). As mentioned above, the object management layer is based upon AIM Net and the storage management layer is based upon the High Performance Storage System (HPSS).
AIM Net Version 0.4 has been ported to the IBM SP1 at the IBM Government Systems' HPSS laboratory in Houston and interfaced to HPSS Release 1. Currently, segments requests are generated by the AIM Net Folio Server and dispatched to the HPSS Bitfile Server, which retrieves the segments from tape and returns them to the Folio Server. Tape striping is used to improve performance. We are currently limited by device, host channel and network rates, and not by any limitations in the AIM Net or HPSSsoftware.
Queries to the system, using a subset of Object Query Language (OQL) are entered through World Wide Web (WWW) forms and hypertext data is retrieved and browsed through WWW viewers. Specialized Query Request Agents are currently under development.
At this time, tests have been done managing approximately half a gigabyte of textual, image, and numerical data. A persistent object store containing multimedia data, including newspaper data and images, is currently under preparation. When HPSS Release 2 is available later in the year, it will be employed for a second suite of tests involving parallel disk and multiple hierarchies.
The goal of this project is to develop a system that manages terabyte-sized collections of multimedia documents and allows users to browse and to retrieve documents related to a topic of interest. In other words, our goal is to design a scalable, high-performance digital library. In this paper, we have described a layered architecture for digital libraries and described the key components and interfaces. Our approach is to view digital data as persistent collections of complex objects and to use lightweight object management to manage this data. To scale as the amount of data increases, we have layered the object management component over the storage management component. We are taking advantage of features of HPSS and of the IEEE Mass Storage Reference Model that allow interfaces at multiple levels within the storage system.
The requirements that the system provide access to terabytes of data (the large stores requirement), be able to scatter and gather internal collections of data to service user queries (the quick access requirement), and be able to move large multimedia objects (the fast transfers requirement) led to our use of a high-performance storage system as the bottom layer in our architecture. The requirements that the system be able to support multimedia documents integrating text, images and video (the complex types requirement), to utilize specialized transport, indexing, and retrieval methods (the transparent services requirement), and to access documents by attributes (the friendly access requirement) led to our use of lightweight, high-performance persistent object manager as the next layer in our architecture.
We have developed an initial prototype called the AIM Net High Performance Digital Library (HPDL), incorporating HPSS and AIM Net, and have begun testing on the IBM SP1 located at IBM in Houston.
It is still an open question how best to interface object management and storage management for scalable, high-performance computing environments. The performance of digital libraries is strongly dependent upon how the data is physically placed and clustered on disks and other media. We have discussed some of the issues, including how data placement and parallelism interact, that affect both the object management and storage management layers. We feel that this is an important topic for future research.
This research was supported in part by the Massive Digital Data System (MDDS) effort sponsored by the Advanced Research and Development Committee of the Community Management Staff.