This is a draft of the paper: R. L. Grossman, The Role of QoS in Wide Area Data Mining, Proceedings of the First Internet 2 Joint Applications Engineering QoS Workshop: Enabling Advanced Applications Through QoS, UCAID, 1999, pages 19-21.
Data mining is the automatic discovery of patterns, associations, changes and anomalies in large data sets ([Dietterich 1997] and [Fayyad 1996] ) . Data mining has traditionally been focused on data which is located in a central warehouse and analyzed within memory. On the other hand most data is distributed. Developing technologies to mine distributed data is a fundamental challenge ([Guo 1998], [Grossman 1998c] and [Stolfo 1997]).
It is important to distinguish searching for data on networks and data mining. An example should make this distinction clear. Finding all documents containing the key word sunspots is a typical search. On the other hand, consider the problem of searching for correlations between twenty five years of sunspot data archived on a server in Boulder and 80 years of Southern night marine air temperature data archived on a server in Maryland. The goal of this data mining query is to understand whether sunspots might be a correlated with climatic shifts in temperature.
Concretely, the data mining process can be viewed as the process of applying data mining algorithms to a learning set extracted from a data warehouse to produce a predictive model [Grossman 1998c]. More accurate predictive models can always be obtained by moving distributed data to a central data warehouse. The problem is that this can be so expensive that most data is never mined. A fundamental trade-off in distributed data mining is whether a) to move data or b) to keep the data in place, analyze the data separately, and merge the results. More precisely, the challenge is move as little data as possible, while still maintaining acceptable accuracy.
QOS plays two different types of roles in distributed data mining:
Interactive Exploration of Data. Both ftp and http can move files. But with web browsers and http people begin to work with networked documents in a fundamentally new way. Today the software infrastructure on the web is focused on exploring (multi-media) documents. Distributed data mining is about the interactive exploration of networked data. For this to be possible, the data mining system must determine whether to move data, the results of queries, or predictive models. Given the data size, the accuracy required, and QOS guarantees, this becomes possible.
Decision Support. Data mining has proven successful for a variety of decision support applications such as detecting fraud and extending credit to consumers. The goal is to make decisions in near real time using as much data as possible. Generally speaking, the more data which is available, the more accurate the predictive models. The problem is that as the number of data sources increases so does the possibility that the entire decision to delays accessing a few of the sites. With QOS, decisions can be reached even if it means not using some of the data due to the cost in accessing it.
Supporting Visualization in Data Mining. Visualization is an important technique in data mining, but today is by and large limited to analyzing local data. Next generation networks supporting QOS would allow the combination of visualization with data analysis and data mining for understanding networked and distributed data.
Mining Image and Continuous Media Data. The three applications above describe how QOS is an important enabling technology for mining distributed data. Working together QOS and data mining can be used to enhance remote access to digital libraries of image and continuous media data. As users interact with these types of digital libraries, agents can observe their queries and the responses of the system. By applying machine learning algorithms to this information, precision and recall can be improved, as well as intelligent caching and prefetching of image and continuous media data. Today, intelligent caching and prefetching is possible for local data - QOS enables a similar strategy for distributed data.
There are several approaches to distributed data mining. In this section, we sketch the approach described in [Grossman 1998a, 1998b and 1998c] from which this section is adapted. Data mining can be computationally intensive and clusters of workstations connected by high performance networks are emerging as a popular platform for data mining [Grossman 1997]. Distributed data mining requires mining data across clusters connected by networks.
The following terminology is useful:
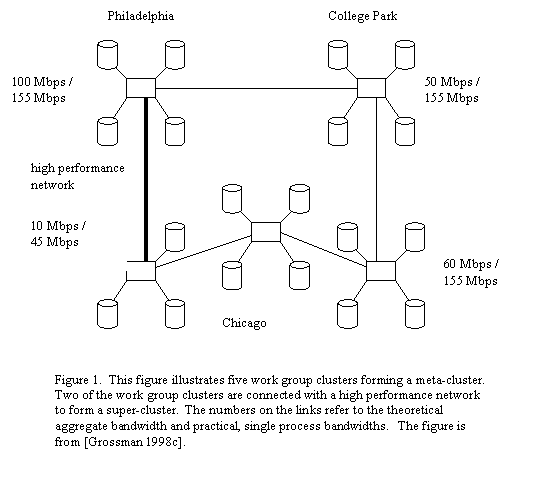
For example we have completed several experimental studies with a Super-Cluster consisting of three workgroup clusters in Chicago, Philadelphia, and College Park, Maryland. See Figure 1. It is important to distinguish between meta-clusters and super-clusters because the performance of the network often dictates different strategies for distributed data mining.
To return to the example in the first section, a scientist using a workstation which is part of the work group cluster in College Park may wish to engage in exploratory data analysis and correlate the sun sport data with a variety of data sets in Philadelphia and Chicago. A traditional approach would require moving the relevant files to College Park with ftp, building a common data set, and applying statistical programs. With distributed data mining and QOS, the appropriate data mining software could make intelligent decisions about returning data, the results of queries, or predictive models to supply approximate results to correlation queries and still be interactive. The strategies would obviously be different depending upon the size of the data sets, the QOS being supported, the time required to reformat the data, and the complexity of the computation required.
Figure 1. This figure illustrates five work group clusters forming a meta-cluster. Two of the work group clusters are connected with a high performance network to form a super-cluster. The numbers on the links refer to the theoretical aggregate bandwidth and practical, single process bandwidths. The figure is from [Grossman 1998c].
In this note, we have a given a brief description of the role of QOS in distributed data mining. Next generation networks supporting QOS should enable users to engage in exploratory data analysis, visualization, and data mining of data which is geographically distributed. The challenge today is not only to design and deploy networks with the appropriate QOS capabilities, but also to develop corresponding algorithms and middleware for distributed data mining. This should fundamentally change the way scientists and engineers analyze data.
[Dietterich 1997] Machine Learning Research: Four Current Directions, to appear.
[Fayyad 1996] U. M. Fayyad, G. Piatetsky-Shapiro, and P. Smyth, "From Data Mining to Knowledge Discovery: An Overview," in Advances in Knowledge Discovery and Data Mining, edited U. M Fayyad, G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy, AAAI Press/MIT Press, pp. 1-34, 1996.
[Grossman 1997] R. L. Grossman, S. Bailey and D. Hanley, Data Mining Using Light Weight Object Management in Clustered Computing Environments, Proceedings of the Seventh International Workshop on Persistent Object Stores, Morgan-Kauffmann, San Mateo, 1997, pp 237-249.
[Grossman 1998a] R. L. Grossman, S. Bailey, A. Ramu and B. Malhi, P. Hallstrom, I. Pulleyn and X. Qin, The Management and Mining of Multiple Predictive Models Using the Predictive Modeling Markup Language (PMML), IST, to appear.
[Grossman 1998b] R. L. Grossman, Supporting the Data Mining Process with Next Generation Data Mining Systems, Enterprise System Journal, to appear, http://www.lac.uic.edu/~grossman/papers/four-gen-dm-v7.htm.
[Grossman 1998c] Robert Grossman, Stuart Bailey, Simon Kaisf, Don Mon, Ashok Ramu and Balinder Malhi, The Preliminary Design of Papyrus: A System for High Performance, Distributed Data Mining over Clusters, Meta-Clusters and Super-Clusters, Proceedings of the 1998 KDD Workshop on Distributed Data Mining, AAAI Press, Menlo Park, California, 1998.
[Guo 1998] Y. Guo, S. M. Ruger, J. Sutiwaraphun and J. Forbes-Millott, Meta-Learnig for Parallel Data Mining, submitted for publication.
[Stolfo 1997] S. Stolfo, A. L. Prodromidis and P. K. Chan, JAM: Java Agents for Meta-Learning over Distributed Databases, in Proceedings of the Third International Conference on Knowledge Discovery and Data Mining, D. Heckerman, H. Mannila, D. Pregibon, and R. Uthurusamy, editors, AAAI Press, Menlo Park, 1997.